
性能优化是前端里一个很难绕开的话题,下面这些优化手段,大多数前端工程师都耳熟能详:
React 相关
- useMemo:缓存计算结果,依赖不变就不重新计算。适合计算本身代价较高的场景,比如对大数组做排序或过滤。常见的误用是把它当成”防止子组件重渲染”的工具——但
useMemo缓存的是值,不是组件,这两件事要分清楚。 - useCallback:缓存函数引用,依赖不变就返回同一个函数。主要配合
React.memo使用,避免每次 render 都生成新函数,导致子组件感知到 props 变化而重渲染。 - Suspense + React.lazy:把组件的 JS bundle 拆分出去,等真正需要渲染时再加载。最典型的用法是路由级别的代码拆分——首屏只加载当前路由所需的代码,其他页面按需加载。
打包构建
- Tree Shaking:构建时静态分析模块引用,删除未被使用的代码,减小 bundle 体积。前提是代码必须使用 ESM 格式(
import/export),CommonJS 的require无法做静态分析。 - 代码压缩:去掉空格、注释,缩短变量名,压缩 JS/CSS 体积。这基本上是 Vite/Webpack 生产模式的默认行为,不需要手动干预太多,但要确认它没有被意外关闭。
渲染与加载
- 减少重渲染:避免不必要的渲染,根本在于合理设计状态结构,再配合
React.memo、useMemo、useCallback使用。 - 懒加载:图片、组件、路由按需加载,不在视口或不需要时不加载。图片懒加载现在可以直接用原生
loading="lazy"属性,不必每次都手写 IntersectionObserver。 - 虚拟列表:超长列表只渲染可见区域的节点,滚动时动态替换内容。这是处理”万级数据”场景的标准解,常用库有
react-window、react-virtual。 - 分页:把大量数据拆成多页加载,减少单次渲染的节点数量。与虚拟列表的区别在于:分页需要用户主动翻页,虚拟列表的体验更连续。
资源请求
- 缓存策略:静态资源用
Cache-Control: max-age做长期缓存,文件名加内容 hash(如main.abc123.js),每次发布变动时换新文件名,浏览器自动使旧缓存失效。接口层用 HTTP 缓存(ETag、Last-Modified)或前端自行维护请求缓存(如 React Query 的staleTime)。 - 静态资源走 CDN:图片、字体、JS bundle 这类静态资源放到 CDN 上,用户从离自己最近的节点拉取,减少网络延迟。对图片而言,CDN 通常还能按需做压缩和格式转换(比如自动转 WebP)。
样式与 HTML
- 用 transform / opacity 做动画:这两个属性的变化不会触发 Layout 和 Paint,只走 Composite 阶段,由 GPU 直接处理,性能最优。反之,改
width、top、left这类属性会触发回流,代价要高得多。 - 减少 DOM 元素:DOM 树越大,每次 Layout 的计算量就越大。无用节点不要留在页面里,能用 CSS 实现的效果就不要用额外 DOM。这条看起来朴素,但在组件化开发中确实容易被忽视——每个组件都包一层
div,层层叠加下来,实际 DOM 规模往往比预期大得多。
这些是八股文里的标准答案,知道不代表真正理解。只有真正在生产环境里遇到过一次卡顿问题,才会意识到性能优化不是背套路,而是一套工程师处理问题的方式。
本文想探讨的不是”性能优化清单”,而是对性能优化这件事更深层的理解:从第一性原理出发,到认清它在大多数日常开发场景里其实是防御性编程,最后回到什么才是前端工程师真正应该建立的性能优化工作流,最终抽象到架构师视角如何看待系统边界和复杂度现状。
一、性能优化到底在优化什么
要回答这个问题,需要理解两个相互独立但经常被混为一谈的模型:
- 浏览器如何从资源构建出可渲染的页面结构
- 浏览器的每一帧渲染循环
模型一:从代码到画面
浏览器把代码变成画面,大致经过以下步骤:
- 解析 HTML,生成 DOM
- 解析 CSS,生成 CSSOM
- DOM + CSSOM 合成 Render Tree(决定要画哪些内容)
- Layout(布局):计算每个元素的几何信息,包括位置和尺寸
- Paint(绘制):把像素逐一写入位图
- Composite(合成):把不同图层交给 GPU 合成,最终呈现到屏幕上
“渲染”不是一个单一动作,而是一整串有依赖关系的流水线。JS 可以在任意阶段修改这些数据结构(DOM、CSSOM、Render Tree),从而触发浏览器重新执行部分渲染流程——浏览器负责渲染,JS 负责改变状态,浏览器根据状态变化重新渲染。
几个关键的阻塞关系:
- 解析 HTML 遇到
<script>标签时,浏览器会暂停 HTML 解析,转而下载并执行 JS,因此 JS 会阻塞 DOM 构建。 - 解析 CSS 生成 CSSOM 时,会阻塞 JS 的执行——浏览器必须保证 JS 能读到正确的样式信息。
- JS 修改元素的
width、height、padding、margin、font-size或 DOM 结构,会触发 Layout(回流)。 - JS 修改
background、color、border、box-shadow等视觉属性,会触发 Paint(重绘),但不需要重新 Layout。
模型二:帧渲染循环
以 60Hz 显示器为例,浏览器每 16.6ms 要完成一帧,整个循环大致如下:
1 | while (tab_open) { |
需要注意的是,浏览器并不是每一帧都严格按”JS → style → layout → paint”顺序完整跑一遍。异步 JS 不会影响当前帧后续的布局和重绘。真实情况是一个事件循环 + 渲染时机的系统。
从这个视角看,性能优化的本质就是:让这条工作流顺畅运行,前面的任务不要阻塞后面的任务。
浏览器是单线程架构,DOM 构建、样式计算、布局、绘制、JS 执行,很多工作都要在主线程上排队完成。一旦某一步变成”长任务”,用户的点击、输入、滚动都会响应迟滞,最终无法在当帧完成合成和展示。
性能优化的最终目的是用户体验,而用户体验可以被拆解为三个具体现象:
- 主线程被长任务占满,导致交互失灵
- 频繁布局与重绘,导致页面掉帧
- 关键内容出现太晚,导致首屏慢
这正好对应了 Web Vitals 的三个核心指标:交互延迟对应 INP,布局稳定性对应 CLS,首屏速度对应 LCP。
二、如何分析并定位一个性能问题
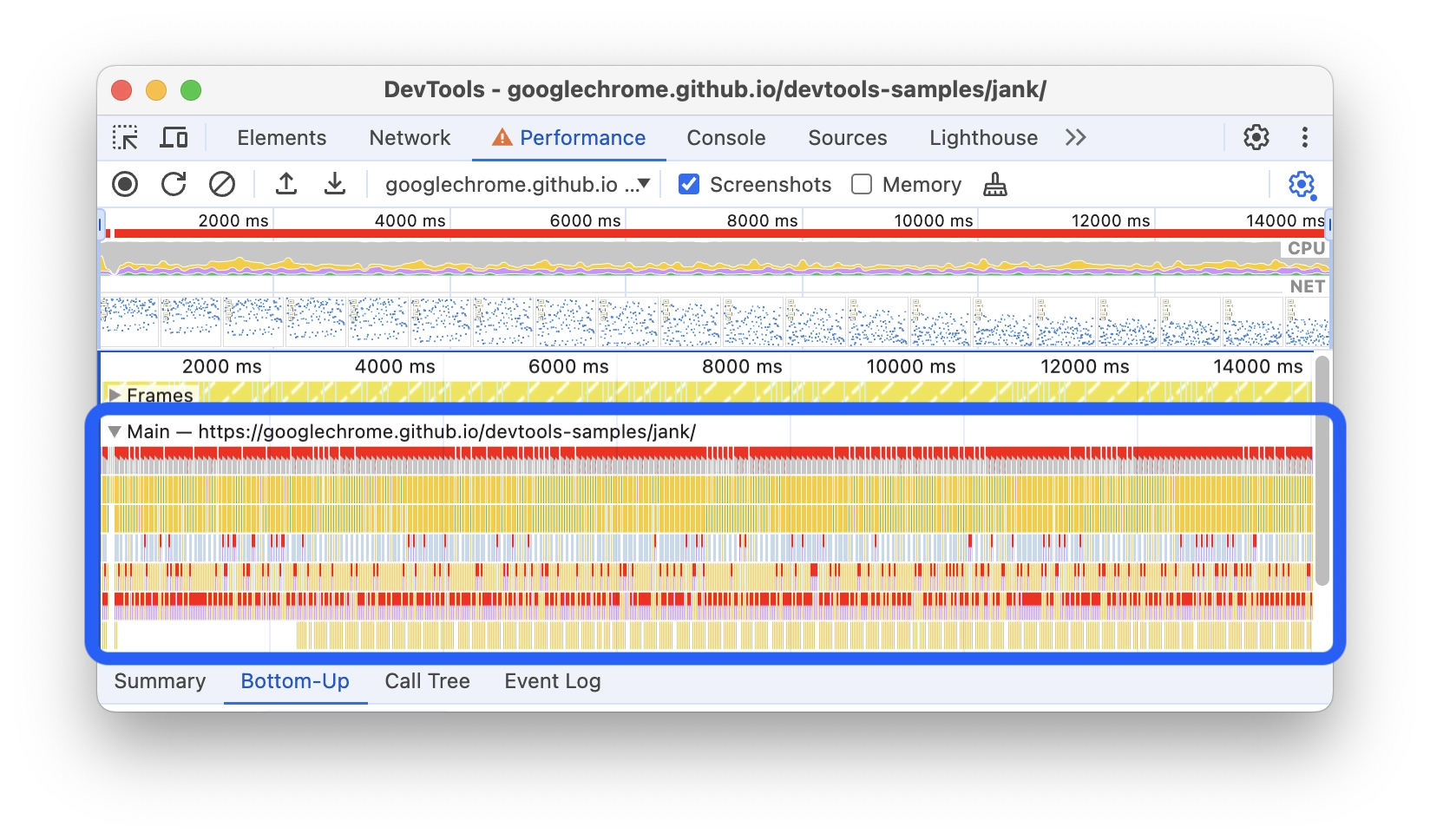
知道了浏览器的三个性能指标,下一步是知道如何排查。打开 Chrome DevTools 的 Performance 面板,录制一段真实场景,通过火焰图来定位问题。
第一步:录制真实场景。 最能暴露问题的三类场景是:首屏加载、点击交互(弹窗、筛选、切换 Tab 等)、滚动长列表。
第二步:先找长任务。 在时间轴的主线程区域找特别宽的任务块。单个任务超过 50ms 就会开始影响交互响应,用户”点了但没反应”,很多时候就是被这段长任务挡住了。
第三步:读火焰图,定位最耗时的调用。 火焰图的坐标系:横轴是时间,从左往右;纵轴是调用栈,从上往下是”调用者 → 被调用者”,越往上越是入口,越往下越是细节。块越宽代表越耗时;块越靠下代表是被上层触发的。定位方式:先找最宽的块,再沿调用栈向上追,找到是谁触发了它。
颜色在火焰图里有明确语义:
- 黄色(Script):JS 执行,包括事件回调、框架 diff、业务逻辑。黄色块很宽,通常意味着 JS 在做重活。
- 紫色(Rendering):样式计算(Recalculate Style)和布局(Layout)。紫色块很多,大概率存在频繁回流。
- 绿色(Painting):绘制(Paint)和合成(Composite)。绿色块异常多,往往是大面积重绘,或动画没有走合成层。
- 灰色:浏览器内部任务或空闲,通常不用重点关注。
第四步:分类:JS 的问题,还是渲染的问题? 定位到长任务之后,需要做进一步判断:
- 主要是黄色 Script 块 → 大概率是 JS 计算量过大、频繁 setState 或第三方库在做重活
- 主要是紫色 Recalculate Style / Layout → 大概率是回流触发过于频繁,或存在 Layout Thrashing
- 主要是绿色 Paint / Composite → 大概率是大面积重绘,或动画没有走合成层
完成这个分类之后,对应的优化方向就自然清晰了。
三、大多数”性能优化”其实是防御性编程
到这里值得停下来思考一个问题:我们做的那些性能优化,有多少是真正在解决问题,又有多少只是在遵守某种编码规范?
回头看常见的那些优化手段:
- 懒加载
- React key
- 按需加载
- 构建时 Tree Shaking
- 虚拟列表
严格来说,这些并不是”性能优化行为”,而是性能设计约束(performance constraints)。它们不是为了解决一个存在的问题,而是为了防止未来出现问题。
这种思想在软件工程里非常普遍:
- 数据库会做 index、connection pool
- 操作系统会做 cache、virtual memory
- CPU 会做 branch prediction、pipeline
这些可能不是因为现状本身就这么复杂,而是因为:如果不这么设计,规模一旦上来一定会慢。
这是工程经验的固化。我工作第一年有很多这样的感觉:”不做这些好像也没问题”,现在才想明白因为当前业务规模还没触发阈值。
所以,这让我想明白了,作为工程师,一个实践的惯例是:在规模没有爆掉之前就提前预防。
但是这里还有一个被引用过度但依然正确的经典原则:
“过早优化是万恶之源。”——Donald Knuth
这句话真正的含义不是”不要优化”,而是不要在没有数据的情况下优化。很多优化手段会引入复杂性——memoization、缓存、虚拟化、异步化——如果这些复杂性没有换来真实收益,系统反而更难维护。
成熟团队通常采用的策略是:先做结构性防御,再做数据驱动优化,让反馈跑起来。 默认启用代码拆分、默认限制 bundle size、默认使用虚拟列表组件;但只有当监控指标出现下滑时,才进行深度性能分析。
还有一个容易被忽视的事实:大多数 Web 应用真正的性能瓶颈并不在前端代码。最常见的前三名是:网络延迟、接口响应时间、资源体积。一个接口需要 800ms 才能返回,前端优化 10ms 的渲染几乎毫无意义。所以极致的用户体验是做到什么程度的性能优化呢?
四、性能问题的具体处理模式
落到实际操作层面,当火焰图里出现异常时,处理逻辑大致如下:
Script 块很宽:先减少无意义更新,再考虑拆任务。
前端最常见的场景是渲染被频繁触发。遇到这种情况,首先要问:是不是 state 放错位置了?很多 re-render 不是 React 的问题,而是状态设计让太多组件被迫一起更新。确认这一点之后,再考虑 React.memo(让子组件在 props 不变时跳过渲染)、useCallback(稳定函数引用)和 useMemo(缓存昂贵的计算结果)。
一次性做太多:分批渲染,匹配帧节奏。
一次性插入几千个节点,容易把主线程打满。实用的约束是:每次处理控制在一帧预算内,约 16ms。具体手段视情况而定:定时器分批是最朴素的,能先把”卡死”变成”可用”;requestAnimationFrame 更贴合浏览器渲染节奏,适合持续更新 UI 的场景;如果本质是长列表,虚拟列表才是更根本的解。
流式长文本渲染是一个典型案例:如果每个 chunk 回来都触发一次 setState,渲染次数会 1:1 跟着 chunk 数走。合理的处理方式是合并更新、降低 setState 频率,再把更新对齐到 requestAnimationFrame 的帧边界提交。
纯计算太重:把重活移出主线程。
当长任务明确是纯计算——解析、压缩、加密、复杂排序——更好的方向是用 Web Worker 把这部分工作移出主线程。主线程只负责交互和渲染,这类优化的收益往往很直接。
Layout / Paint 块很多:减少回流与重绘。
Layout 频繁的话,先检查是否在循环里交替读写布局属性(getBoundingClientRect、offsetHeight 等),这是 Layout Thrashing 最常见的来源。如果动画掉帧,优先把动画属性换成 transform/opacity,走合成层,避免触发 Layout 和 Paint。will-change 要谨慎使用,它会占用额外内存,滥用反而适得其反。
五、什么是真正有价值的性能优化
把”写了性能优化代码”当作目标本身,是一种常见的误区。更准确的衡量标准只有一个:能否用工具证明它真正解决了瓶颈。
判断一次性能优化是否有价值,三个标准:
- 目标清晰:明确知道在解决哪种卡顿——是 INP、LCP,还是掉帧?
- 改动克制:用最小的改动验证假设,而不是把整个模块重写一遍。
- 可验证:改之前录一次 Profile,改之后再录一次,用数据说话。
没有这三点,所谓的”性能优化”很可能只是在引入不必要的复杂性。
六、前端性能优化的层级模型
如果按真实工程复杂度,把前端性能优化划分层级,结构大致如下:
1 | Level 1 代码级优化 React key / memo / 懒加载 |
Level 1–2的工作本质上是在执行经过验证的工程约束,而不是在解决真正的性能瓶颈。
真正的性能工程发生在 Level 4–5,需要对浏览器渲染机制、JS 运行时、框架调度器有深入理解,并且通常需要有足够的系统规模或用户量作为前提。
理解这个层级,对于判断自己当前在做什么、以及下一步应该深入哪个方向,都有实际的参考价值。
性能优化只是前端工程体系里的一个切面。把它理解清楚之后,你会发现它指向的其实是更底层的几个方向:浏览器原理、JS 运行时、框架机制、前端工程化、以及大规模系统设计。这些才是真正值得长期投入的知识结构。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。
